






4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 747773位读者 | 引用
2
Jul
用Pandas实现高效的Apriori算法
By 苏剑林 | 2015-07-02 | 176585位读者 | 引用最近在做数据挖掘相关的工作,阅读到了Apriori算法。平时由于没有涉及到相关领域,因此对Apriori算法并不了解,而如今工作上遇到了,就不得不认真学习一下了。Apriori算法是一个寻找关联规则的算法,也就是从一大批数据中找到可能的逻辑,比如“条件A+条件B”很有可能推出“条件C”(A+B-->C),这就是一个关联规则。具体来讲,比如客户买了A商品后,往往会买B商品(反之,买了B商品不一定会买A商品),或者更复杂的,买了A、B两种商品的客户,很有可能会再买C商品(反之也不一定)。有了这些信息,我们就可以把一些商品组合销售,以获得更高的收益。而寻求关联规则的算法,就是关联分析算法。
啤酒与尿布

啤酒与尿布
关联算法的案例中,最为人老生常谈的应该是“啤酒与尿布”了。“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,超市管理人员发现“啤酒与尿布两件看上去毫无关系的商品会经常出现在同一个购物篮中”。经过分析,原来在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。因此,沃尔玛尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以同时找到这两件商品。事实是效果相当不错!
22
Jun
文本情感分类(一):传统模型
By 苏剑林 | 2015-06-22 | 301046位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
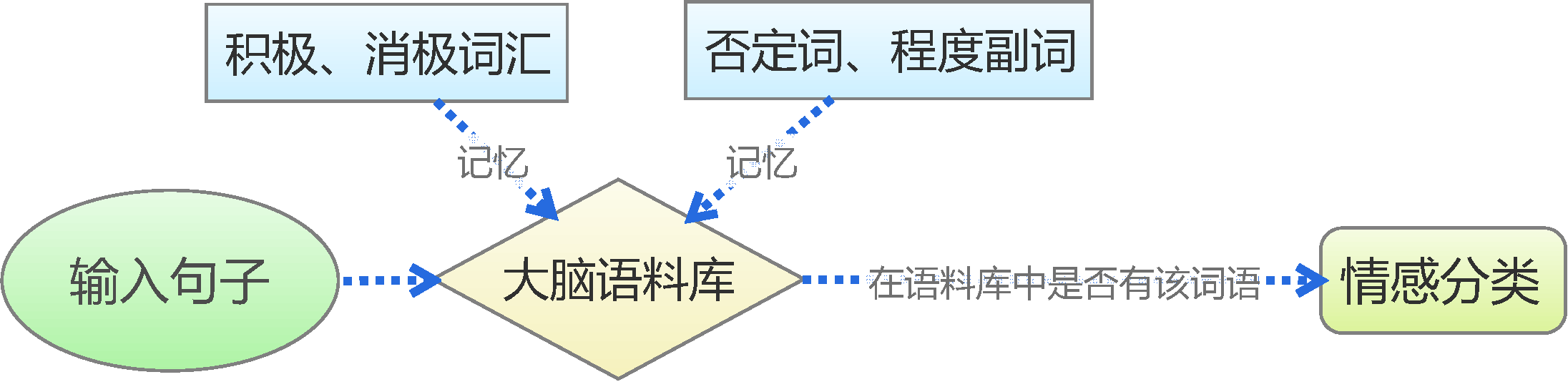
人的最简单的判断思维
思维导图
这学期的数学建模课,对笔者来说,基本上就是一个锻炼论文写作和Python技能的过程。不过是写论文还是写博客,我都致力于写出符合自己审美观的作品,因此我才会选择$\LaTeX$,我才会选择Python。$\LaTeX$写出来的科学论文是公认的标准而好看的格式,而Python,的确可以作出漂亮的图,也可以简洁地完成所需要的数值计算。我越来越发现,在数学建模、写作方面,除了必不可少的符号推导部分(这部分只能用Mathematica),我已经离不开Python了。
为什么还要求漂亮?内容好不就行了吗?的确,内容才是主要的,但是如果能把展示效果美化一下,而且又不耗费更多的功夫,那么何乐而不为呢?
18
Dec
迟到一年的建模:再探碎纸复原
By 苏剑林 | 2014-12-18 | 106444位读者 | 引用前言:一年前国赛的时候,很初级地做了一下B题,做完之后还写了个《碎纸复原:一个人的数学建模》。当时就是对题目很有兴趣,然后通过一天的学习,基本完成了附件一二的代码,对附件三也只是有个概念。而今年我们上的数学建模课,老师把这道题作为大作业让我们做,于是我便再拾起了一年前的那份激情,继续那未完成的一个人的数学建模...
与去年不同的是,这次将所有代码用Python实现了,更简洁,更清晰,甚至可能更高效~~以下是论文全文。
研究背景
2011年10月29日,美国国防部高级研究计划局(DARPA)宣布了一场碎纸复原挑战赛(Shredder Challenge),旨在寻找到高效有效的算法,对碎纸机处理后的碎纸屑进行复原。[1]该竞赛吸引了全美9000支参赛队伍参与角逐,经过一个多月的时间,有一支队伍成功完成了官方的题目。
近年来,碎纸复原技术日益受到重视,它显示了在碎片中“还原真相”的可能性,表明我们可以从一些破碎的片段中“解密”出原始信息来。另一方面,该技术也和照片处理领域中的“全景图拼接技术”有一定联系,该技术是指通过若干张不同侧面的照片,合成一张完整的全景图。因此,分析研究碎纸复原技术,有着重要的意义。
28
Oct
在Python中使用GMP(gmpy2)
By 苏剑林 | 2014-10-28 | 78871位读者 | 引用之前笔者曾写过《初试在Python中使用PARI/GP》,简单介绍了一下在Python中调用PARI/GP的方法。PARI/GP是一个比较强大的数论库,“针对数论中的快速计算(大数分解,代数数论,椭圆曲线...)而设计”,它既可以被C/C++或Python之类的编程语言调用,而且它本身又是一种自成一体的脚本语言。而如果仅仅需要高精度的大数运算功能,那么GMP似乎更满足我们的需求。
了解C/C++的读者都会知道GMP(全称是GNU Multiple Precision Arithmetic Library,即GNU高精度算术运算库),它是一个开源的高精度运算库,其中不但有普通的整数、实数、浮点数的高精度运算,还有随机数生成,尤其是提供了非常完备的数论中的运算接口,比如Miller-Rabin素数测试算法、大素数生成、欧几里德算法、求域中元素的逆、Jacobi符号、legendre符号等[来源]。虽然在C/C++中调用GMP并不算复杂,但是如果能在以高开发效率著称的Python中使用GMP,那么无疑是一件快事。这正是本文要说的gmpy2。
17
Oct
两百万素数之和与“电脑病”
By 苏剑林 | 2014-10-17 | 18378位读者 | 引用原则上来讲,同样的算法,如果分别在Python和C++上实现,那么Python的速度肯定比不上C++的。但是Python还被称为“胶水语言”,它允许我们把主要计算的部分用C或C++等高效的语言编写好,然后它作为“粘合剂”把两者粘合在一起。正因为如此,Python才有了各种各样的扩展库,这些库中有不少是用C语言编写的。因此,我们在编写Python程序的时候,如果可以用这些现成的库,速度会快很多。本文就是用Numpy来改进之前的《两百万前素数之和与前两百万素数之和》的计算。
算法本身是没有变的,只是用了Numpy来处理数组计算,代码如下:
7
Oct

最近评论