






4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 636053位读者 | 引用
最近一直在考虑一些自然语言处理问题和一些非线性分析问题,无暇总结发文,在此表示抱歉。本文要说的是对于一阶非线性差分方程(当然高阶也可以类似地做)的一种摄动格式,理论上来说,本方法可以得到任意一阶非线性差分方程的显式渐近解。
非线性差分方程
对于一般的一阶非线性差分方程
$$\begin{equation}\label{chafenfangcheng}x_{n+1}-x_n = f(x_n)\end{equation}$$
通常来说,差分方程很少有解析解,因此要通过渐近分析等手段来分析非线性差分方程的性质。很多时候,我们首先会考虑将差分替换为求导,得到微分方程
$$\begin{equation}\label{weifenfangcheng}\frac{dx}{dn}=f(x)\end{equation}$$
作为差分方程$\eqref{chafenfangcheng}$的近似。其中的原因,除了微分方程有比较简单的显式解之外,另一重要原因是微分方程$\eqref{weifenfangcheng}$近似保留了差分方程$\eqref{chafenfangcheng}$的一些比较重要的性质,如渐近性。例如,考虑离散的阻滞增长模型:
$$\begin{equation}\label{zuzhizengzhang}x_{n+1}=(1+\alpha)x_n -\beta x_n^2\end{equation}$$
对应的微分方程为(差分替换为求导):
$$\begin{equation}\frac{dx}{dn}=\alpha x -\beta x^2\end{equation}$$
此方程解得
$$\begin{equation}x_n = \frac{\alpha}{\beta+c e^{-\alpha n}}\end{equation}$$
其中$c$是任意常数。上述结果已经大概给出了原差分方程$\eqref{zuzhizengzhang}$的解的变化趋势,并且成功给出了最终的渐近极限$x_n \to \frac{\alpha}{\beta}$。下图是当$\alpha=\beta=1$且$c=1$(即$x_0=\frac{1}{2}$)时,微分方程的解与差分方程的解的值比较。
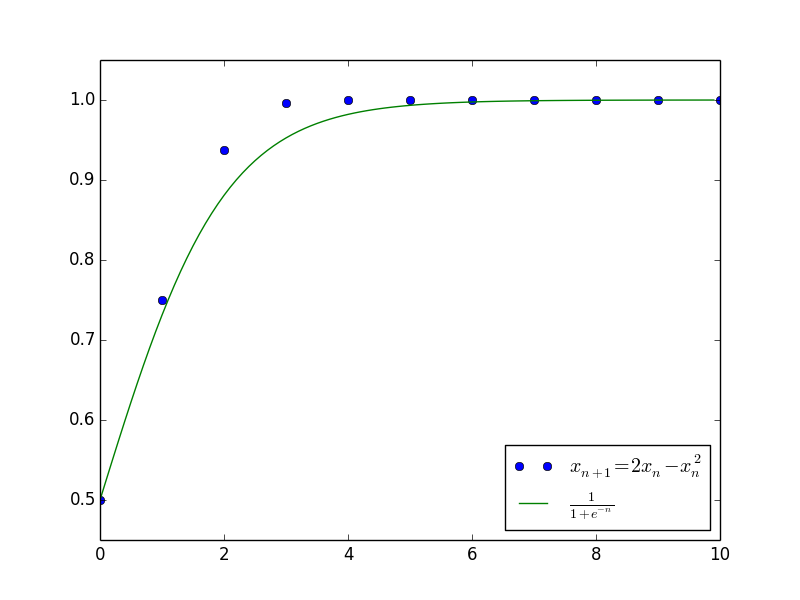
差分方程的摄动法1
现在的问题是,既然微分方程的解可以作为一个形态良好的近似解了,那么是否可以在微分方程的解的基础上,进一步加入修正项提高精度?
1
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(一)
By 苏剑林 | 2015-12-01 | 87114位读者 | 引用熵的概念
作为一名物理爱好者,我一直对统计力学中“熵”这个概念感到神秘和好奇。因此,当我接触数据科学的时候,我也对最大熵模型产生了浓厚的兴趣。
熵是什么?在通俗的介绍中,熵一般有两种解释:(1)熵是不确定性的度量;(2)熵是信息的度量。看上去说的不是一回事,其实它们说的就是同一个意思。首先,熵是不确定性的度量,它衡量着我们对某个事物的“无知程度”。熵为什么又是信息的度量呢?既然熵代表了我们对事物的无知,那么当我们从“无知”到“完全认识”这个过程中,就会获得一定的信息量,我们开始越无知,那么到达“完全认识”时,获得的信息量就越大,因此,作为不确定性的度量的熵,也可以看作是信息的度量,说准确点,是我们能从中获得的最大的信息量。
7
Mar
通过ssh动态端口转发共享校园资源(附带干货)
By 苏剑林 | 2016-03-07 | 37500位读者 | 引用众所周知,校园网最宝贵的资源应该有两样:一是IPv6,IPv6是访问Google等网站的最理想途径,当然IPv6并非所有高校都有;二是论文库,一般高校都会买了一部分论文库(知网、万方等)的下载权,供校园用户使用。如果说访问Google还有VPN等诸多方式的话,那么对于校外用户来说访问知网等资源就显得格外宝贵了,一般只是叫校内用户下载,或者就只能付费了(那个贵呀!)。
站长还是学生,在学校同时享用着IPv6和论文库资源,确实很爽。自从用上Openwrt的路由之后,一直想着怎么把校园网资源共享出去。曾经考虑过搭建PPTP VPN,但是感觉略有复杂(当然,跟其他VPN相比,搭建PPTP VPN算是非常简单的了,可是我还是不怎么喜欢。),而且当时还没解决内网穿透的问题。最近借助ssh反向代理的方式实现了内网穿透,继而认识到,通过ssh动态端口转发,居然还可以搭建代理,并且实现远程访问内网(校园网)资源,而且几乎不用在路由器本身上面做任何配置。不得不说,ssh真是一个极其强大的东西呀。
添加普通帐号
既然要共享,就没理由把root账户都分享出去了,因此,第一步要实现的是在Openwrt上添加一个代理账号,而且为了安全和保密,这个账号不允许真的登陆服务器进行操作,而只允许进行端口转发。
9
Jan
《量子力学与路径积分》习题解答V0.4
By 苏剑林 | 2016-01-09 | 33814位读者 | 引用
流年
《量子力学与路径积分》的习题解答终于艰难地推进到了0.4版本,目前已经基本完成了前7章的习题。
今天已经是2016年1月9号了,2015年已经远去,都忘记跟大家说一声新年快乐了,实在抱歉。在这里补充一句:祝大家新年快乐,事事如意!。
笔者已经大四了,现在是临近期末考,又临近毕业。最近忙的事情有很多,其中之一是我加入了一个互联网小公司的创业队伍中,负责文本挖掘,偶尔也写写爬虫,等等,感觉自己进去之后,增长了不少见识,也增加了不少技术知识,较之我上一次实习,又有不一样的高度。现在里边有好几样事情排队着做,可谓忙得不亦悦乎了。还有,我也开始写毕业论文了,早点写完能够多点时间,学学自己喜欢的东西,毕业论文我写的是路径积分相关的内容,自我感觉写得还是比较清楚易懂的,等时机成熟了,发出来,向大家普及路径积分^_^。此外,每天做点路径积分的习题,也要消耗不少时间,有些比较难的题目,基本一道就做几个早上才能写出比较满意的答案。总感觉想学的想做的事情有很多,可是时间很少。
7
Feb
年三十折腾极路由之SSH反向代理
By 苏剑林 | 2016-02-07 | 63731位读者 | 引用
猴年快乐!
今天是年三十了,这里简单祝大家除夕快乐,新年快乐!愿大家在新的一年里都晋升为学神。^_^
这两天主要在折腾家里的路由器。平时家里只有爸妈两人,所以为了节省,家里只是通过中继隔壁家的网络来上网。本来家里用小米路由器mini,可是小米mini中继模式下功能限制非常多,我又不想刷第三方固件(因为这样会失去app控制功能,不是很方便),所以干脆换了个极路由3。极路由在中继模式下仍然保留了大部分功能(我觉得这样才是正常的,我不理解小米mini在中继之后就没了那么多功能究竟是什么逻辑)。
作为折腾派,一个新路由到手,总有很多东西要配置,极路由本身是基于openwrt的,因此可玩性也很强。首先要完成中继,然后上网,这个很简单就不多说了。其次是获得ssh权限,在极路由那里叫做“申请开发者模式”,或者叫root(感觉极路由想做路由界的苹果,但是在如今这个时代,苹果当初那种发展模式估计很难发展起来了),这个步骤也不难,不过申请之后就会失去极路由的保修资格(不理解这是什么逻辑)。
本文主要介绍了怎么在openwrt(极路由)上安装python,以及建立SSH反向代理(实现内网穿透)。
20
Feb
熵的形象来源与熵的妙用
By 苏剑林 | 2016-02-20 | 32497位读者 | 引用在拙作《“熵”不起:从熵、最大熵原理到最大熵模型(一)》中,笔者从比较“专业”的角度引出了熵,并对熵做了诠释。当然,熵作为不确定性的度量,应该具有更通俗、更形象的来源,本文就是试图补充这一部分,并由此给出一些妙用。
熵的形象来源
我们考虑由0-9这十个数字组成的自然数,如果要求小于10000的话,那么很自然有10000个,如果我们说“某个小于10000的自然数”,那么0~9999都有可能出现,那么10000便是这件事的不确定性的一个度量。类似地,考虑$n$个不同元素(可重复使用)组成的长度为$m$的序列,那么这个序列有$n^m$种情况,这时$n^m$也是这件事情的不确定性的度量。
$n^m$是指数形式的,数字可能异常地大,因此我们取了对数,得到$m\log n$,这也可以作为不确定性的度量,它跟我们原来熵的定义是一致的。因为
$$m\log n=-\sum_{i=1}^{n^m} \frac{1}{n^m}\log \frac{1}{n^m}$$
读者可能会疑惑,$n^m$和$m\log n$都算是不确定性的度量,那么究竟是什么原因决定了我们用$m\log n$而不是用$n^m$呢?答案是可加性。取对数后的度量具有可加性,方便我们运算。当然,可加性只是便利的要求,并不是必然的。如果使用$n^m$形式,那么就相应地具有可乘性。
18
May
调侃:万有引力与爱因斯坦的理论
By 苏剑林 | 2016-05-18 | 51276位读者 | 引用我不是研究引力的,也没有很好地学习过引力。在理论物理方面,我学习经典力学和量子力学比学习广义相对论要多得多。因此,本来我是不应该谈引力的,以免误人子弟。不过,在一次坐车的途中,司机的刹车和加速让我联想到了一些跟引力有关的东西,自我感觉比较有趣,所以发给大家分享一下,也请大家指正。
等效原理

坐汽车
引力,准确来说应该是“万有引力”。所谓“万有”,有两个含义:1、所有物体都能够产生引力;2、所有物体都被引力影响。一个力居然是“万有”的,这让爱因斯坦感觉到非常奇怪,这也是四种基本力之中,引力跟其他力区别最明显的地方。相比之下,电磁相互作用力就只能存在于有“电”的地方,弱相互作用只存在于费米子,等等。
除了引力之外,我们平时还遇到过什么“万有”的力吗?貌似没有。但是我们想象一下,当你坐在一辆长途大巴匀速前进时,突然司机来了一个急刹车,在刹车的那一瞬间,所有人都往前倾了,不仅如此,可能你的行李箱、你的随身物品都往前移的,事实上,车上所有东西都受到了一个往前的力!对于那辆车上的人和物来说,刹车的那一瞬间,就存在着一个“万有”的力!

最近评论