






8
Dec
伽马函数的傅里叶变换之路
By 苏剑林 | 2014-12-08 | 73082位读者 | 引用伽马函数
$$\Gamma(x)=\int_0^{+\infty}t^{x-1}e^{-t}dt$$
作为阶乘的推广,会让很多初学者感到困惑,对于笔者来说也不例外。一个最自然的问题就是:这般复杂的推广公式是如何得到的?
在cos.name的文章《神奇的伽马函数》中,有比较详细地对伽马函数的历史介绍,笔者细读之后也获益匪浅。但美中不足的是,笔者还是没能从中找到引出伽马函数的一种“自然”的办法。所谓“自然”,并不是说最简单的,而是根据一些基本的性质和定义,直接把伽马函数的表达式反解出来。它的过程和运算也许并不简单,但是思想应当是直接而简洁的。当然,我们不能苛求历史上伽马函数以这种方式诞生,但是作为事后探索是有益的,有助于我们了解伽马函数的特性。于是笔者尝试了以下途径,得到了一些结果,可是也得到了一些困惑。
23
Dec
鬼斧神工:求n维球的体积
By 苏剑林 | 2014-12-23 | 116725位读者 | 引用今天早上同学问了我有关伽马函数和$n$维空间的球体积之间的关系,我记得我以前想要研究,但是并没有落实。既然她提问了,那么就完成这未完成的计划吧。
标准思路
简单来说,$n$维球体积就是如下$n$重积分
$$V_n(r)=\int_{x_1^2+x_2^2+\dots+x_n^2\leq r^2}dx_1 dx_2\dots dx_n$$
用更加几何的思路,我们通过一组平行面($n-1$维的平行面)分割,使得$n$维球分解为一系列近似小柱体,因此,可以得到递推公式
$$V_n (r)=\int_{-r}^r V_{n-1} \left(\sqrt{r^2-t^2}\right)dt$$
设$t=r\sin\theta_1$,就有
$$V_n (r)=r\int_{-\frac{\pi}{2}}^{\frac{\pi}{2}} V_{n-1} \left(r\cos\theta_1\right)\cos\theta_1 d\theta_1$$
27
Mar
海伦公式的一个别致的物理推导
By 苏剑林 | 2015-03-27 | 54632位读者 | 引用海伦公式是已知三角形三边的长度$a,b,c$来求面积$S$的公式,是一个相当漂亮的公式,它不算复杂,同时它关于$a,b,c$是对称的,充分体现了三边的同等地位。可是,这样具有对称美的公式推导,往往要经过一个不对称的过程,比如维基百科上的证明,这未免有点美中不足。本文的目的,就是想为此补充一个对称的推导。本文题目为“物理推导”,关键在于“推导”而不是“证明”,同时这里的“物理”并非是通过物理类比而来,而是推导的思想和方法很具有“物理味道”。
$$\sqrt{p(p-a)(p-b)(p-c)}$$
在推导开始之前,笔者给出一个评论:海伦公式似乎是由三边长求三角形面积的所有可能的公式之中最简单的一个。
10
Jun
【翻译】巨型望远镜:要继续,就得有牺牲!
By 苏剑林 | 2015-06-10 | 28839位读者 | 引用
2007年末公布的30米望远镜效果图
文章来自:新科学家,这是一篇关于30米望远镜(Thirty Meter Telescope,TMT)的新闻,起因是望远镜的制造遭到当地人的不满,当然背后的原因是很深远的,难以说清楚。更多有关TMT的新闻,可以阅读:http://www.ctmt.org/
夏威夷的巨型望远镜:要继续,就得有牺牲!
四分之一必须离开!在停止了两个月之后,夏威夷的巨型30米望远镜(Thirty Meter Telescope,TMT)重新回归到建设进程——但要牺牲其他望远镜。
由于夏威夷当地居民的抗议声越来越大,早在四月望远镜的建设工作就被迫暂停。与该望远镜相比,目前世界上所有的望远镜都相形见绌——它让能够让天文学家们凝视可见的宇宙的边缘。它位于许多夏威夷人认为是“神圣之地”的死火山莫纳克亚山,因此被夏威夷人认为是一种侮辱——尤其是在山顶已经有十多个望远镜了。
3
Aug
运动相机测试:家乡的星空
By 苏剑林 | 2016-08-03 | 40211位读者 | 引用记得很早之前就想尝试一下拍星空,无奈一直都没有设备。以前只知道单反可以拍星空,因此,一直以来的想法就是有钱了就去买台单反。因为各种原因一拖再拖,最后慢慢觉得,对于我这种三分钟热度的人来说,单反的意义还真的不是很大。
这两年,在小米的鼓吹下,小蚁运动相机在国内算是慢慢掀起了一股运动相机潮。这种相机的特点是小巧、灵活,价格也不贵(相比单反)。灵活不仅仅是说它便于携带,而且还是功能上的灵活,比如一代小蚁还支持编程拍摄!(写程序控制快门、ISO、拍摄间隔,并实现定时拍摄等)这样当然很快就吸引了我,在小蚁2代众筹之时,我也咬咬牙,入了一台。
前两天回到家,刚好晴夜,马上就试了一下拍星空的效果。下面是在我家楼顶拍的,用ISO400曝光30秒的效果:

家乡的星空
12
Apr
【备忘】用树莓派3做无线路由器
By 苏剑林 | 2016-04-12 | 68293位读者 | 引用3月初发布的树莓派3自带了WiFi和蓝牙,再加上它本来就有一个网口,因此俨然就是一台无线路由器了。我也忍不住入手了一个,打算用来做路由器和NAS。树莓派做路由器的教程已经有很多了,当然,基本都是基于树莓派2的,3之前的版本都没有自带WiFi,因此需要自己配无线网卡,而3自带了无线网卡,配置就方便多了。参考了两篇外文教程,成功配置,在这里记录一下。
参考教程:
https://frillip.com/using-your-raspberry-pi-3-as-a-wifi-access-point-with-hostapd/
https://gist.github.com/Lewiscowles1986/fecd4de0b45b2029c390#file-rpi3-ap-setup-sh
24
Jun
OCR技术浅探:4. 文字定位
By 苏剑林 | 2016-06-24 | 43443位读者 | 引用经过第一部分,我们已经较好地提取了图像的文本特征,下面进行文字定位. 主要过程分两步:1、邻近搜索,目的是圈出单行文字;2、文本切割,目的是将单行文本切割为单字.
邻近搜索
我们可以对提取的特征图进行连通区域搜索,得到的每个连通区域视为一个汉字. 这对于大多数汉字来说是适用,但是对于一些比较简单的汉字却不适用,比如“小”、“旦”、“八”、“元”这些字,由于不具有连通性,所以就被分拆开了,如图13. 因此,我们需要通过邻近搜索算法,来整合可能成字的区域,得到单行的文本区域.

图13 直接搜索连通区域,会把诸如“元”之类的字分拆开
邻近搜索的目的是进行膨胀,以把可能成字的区域“粘合”起来. 如果不进行搜索就膨胀,那么膨胀是各个方向同时进行的,这样有可能把上下行都粘合起来了. 因此,我们只允许区域向单一的一个方向膨胀. 我们正是要通过搜索邻近区域来确定膨胀方向(上、下、左、右):
邻近搜索* 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向.
既然涉及到了邻近,那么就需要有距离的概念. 下面给出一个比较合理的距离的定义.
距离
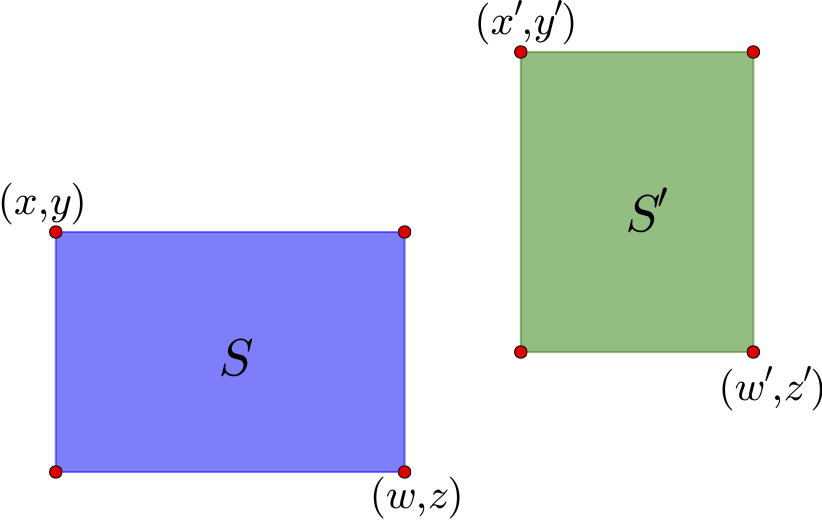
图14 两个示例区域
如上图,通过左上角坐标$(x,y)$和右下角坐标$(z,w)$就可以确定一个矩形区域,这里的坐标是以左上角为原点来算的. 这个区域的中心是$\left(\frac{x+w}{2},\frac{y+z}{2}\right)$. 对于图中的两个区域$S$和$S'$,可以计算它们的中心向量差
$$(x_c,y_c)=\left(\frac{x'+w'}{2}-\frac{x+w}{2},\frac{y'+z'}{2}-\frac{y+z}{2}\right)\tag{10}$$
如果直接使用$\sqrt{x_c^2+y_c^2}$作为距离是不合理的,因为这里的邻近应该是按边界来算,而不是中心点. 因此,需要减去区域的长度:
$$(x'_c,y'_c)=\left(x_c-\frac{w-x}{2}-\frac{w'-x'}{2},y_c-\frac{z-y}{2}-\frac{z'-y'}{2}\right)\tag{11}$$
距离定义为
$$d(S,S')=\sqrt{[\max(x'_c,0)]^2+[\max(y'_c,0)]^2}\tag{12}$$
至于方向,由$(x_c,y_c)$的幅角进行判断即可.
然而,按照前面的“邻近搜索*”方法,容易把上下两行文字粘合起来,因此,基于我们的横向排版假设,更好的方法是只允许横向膨胀:
邻近搜索 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向,当且仅当所在方向是水平的,才执行膨胀操作.
结果
有了距离之后,我们就可以计算每两个连通区域之间的距离,然后找出最邻近的区域. 我们将每个区域向它最邻近的区域所在的方向扩大4分之一,这样邻近的区域就有可能融合为一个新的区域,从而把碎片整合.
实验表明,邻近搜索的思路能够有效地整合文字碎片,结果如图15.

图15 通过邻近搜索后,圈出的文字区域
24
Jun



最近评论