






15
Jan
SVD分解(一):自编码器与人工智能
By 苏剑林 | 2017-01-15 | 40653位读者 | 引用咋看上去,SVD分解是比较传统的数据挖掘手段,自编码器是深度学习中一个比较“先进”的概念,应该没啥交集才对。而本文则要说,如果不考虑激活函数,那么两者将是等价的。进一步的思考就可以发现,不管是SVD还是自编码器,我们降维,并不是纯粹地为了减少储存量或者减少计算量,而是“智能”的初步体现。
等价性
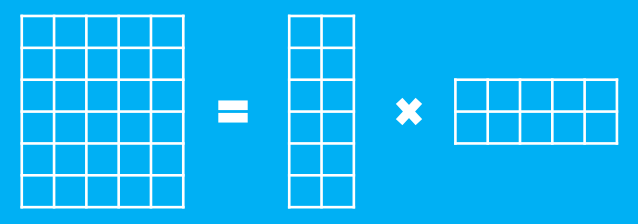
假设有一个$m$行$n$列的庞大矩阵$M_{m\times n}$,这可能使得计算甚至存储上都成问题,于是考虑一个分解,希望找到矩阵$A_{m\times k}$和$B_{k\times n}$,使得
$$M_{m\times n}=A_{m\times k}\times B_{k\times n}$$
这里的乘法是矩阵乘法。如图
SVD
13
Jan
【中文分词系列】 6. 基于全卷积网络的中文分词
By 苏剑林 | 2017-01-13 | 52002位读者 | 引用之前已经写过用LSTM来做分词的方案了,今天再来一篇用CNN的,准确来说是FCN,全卷积网络。其实这个模型的主要目的并非研究中文分词,而是练习tensorflow。从两年前就开始用Keras了,可以说对它比较熟了,也渐渐发现了它的一些不足,比如处理变长输入时不方便、加入自定义的约束比较困难等,所以干脆试试原生的tensorflow了,试了之后发现其实也不复杂。嗯,都是python,能有多复杂。本文就是练习一下如何用tensorflow处理不定长输入任务,以中文分词为例,并在最后加入了硬解码,将深度学习与词典分词结合了起来。
CNN
另外,就是关于FCN的。放到语言任务中看,(一维)卷积其实就是ngram模型,从这个角度来看其实CNN远比RNN来得自然,RNN好像就是为序列任务精心设计的,而CNN则是传统ngram模型的一个延伸。另外不管CNN和RNN都有权值共享,看上去只是为了降低运算量的一个折中选择,但事实上里边大有道理。CNN中的权值共享是平移不变性的必然结果,而不是仅仅是降低运算量的一个选择,试想一下,将一幅图像平移一点点,或者在一个句子前插入一个无意义的空格(导致后面所有字都向后平移了一位),这样应该给出一个相似甚至相同的结果,而这要求卷积必然是权值共享的,即权值不能跟位置有关系。
14
Dec
端到端的腾讯验证码识别(46%正确率)
By 苏剑林 | 2016-12-14 | 66711位读者 | 引用最新结果请参考:http://kexue.fm/archives/4503/
前段时间有幸得到了一个网友提供的一批带标签的腾讯验证码样本(验证码样板:http://captcha.qq.com/getimage),于是抽了点时间,测试了一下验证码识别的模型。

腾讯验证码
样本
这批验证码比较简单,4位的英文字母,有大小写,但输入的时候不区分大小写,图案有一定的混淆,传统的基于分割的方案估计比较难办。端到端的方案是,直接将验证码输入,做几个卷积层,然后连接几个分类器(26分类),然后就直接输出四个字母标签了。其实还真没有什么好说的,有样本就能做了,而且这个框架是通用的,可以用到区分大小写的情形(52分类),也可以用到英文数字混合的情形(再加10个类别而已)。
3
Dec
词向量与Embedding究竟是怎么回事?
By 苏剑林 | 2016-12-03 | 237940位读者 | 引用词向量,英文名叫Word Embedding,按照字面意思,应该是词嵌入。说到词向量,不少读者应该会立马想到Google出品的Word2Vec,大牌效应就是不一样。另外,用Keras之类的框架还有一个Embedding层,也说是将词ID映射为向量。由于先入为主的意识,大家可能就会将词向量跟Word2Vec等同起来,而反过来问“Embedding是哪种词向量?”这类问题,尤其是对于初学者来说,应该是很混淆的。事实上,哪怕对于老手,也不一定能够很好地说清楚。
这一切,还得从one hot说起...
五十步笑百步
one hot,中文可以翻译为“独热”,是最原始的用来表示字、词的方式。为了简单,本文以字为例,词也是类似的。假如词表中有“科、学、空、间、不、错”六个字,one hot就是给这六个字分别用一个0-1编码:
$$\begin{array}{c|c}\hline\text{科} & [1, 0, 0, 0, 0, 0]\\
\text{学} & [0, 1, 0, 0, 0, 0]\\
\text{空} & [0, 0, 1, 0, 0, 0]\\
\text{间} & [0, 0, 0, 1, 0, 0]\\
\text{不} & [0, 0, 0, 0, 1, 0]\\
\text{错} & [0, 0, 0, 0, 0, 1]\\
\hline
\end{array}$$
1
Dec
基于双向GRU和语言模型的视角情感分析
By 苏剑林 | 2016-12-01 | 74482位读者 | 引用前段时间参加了一个傻逼的网络比赛——基于视角的领域情感分析,主页在这里。比赛的任务是找出一段话的实体然后判断情感,比如“我喜欢本田,我不喜欢丰田”这句话中,要标出“本田”和“丰田”,并且站在本田的角度,情感是积极的,站在丰田的角度,情感就是消极的。也就是说,等价于将实体识别和情感分析结合起来了。
吐槽
看起来很高端,哪里傻逼了?比赛任务本身还不错,值得研究,然而官方却很傻逼,主要体现为:1、比赛分初赛、复赛、决赛三个阶段,初赛一个多月时间,然后筛选部分进入复赛,复赛就简单换了一点数据,题目、数据的领域都没有变化,复赛也是一个月的时间,这傻逼复赛究竟有什么意义?2、大家可以看看选手们在群里讨论什么:
25
Nov
三顾碎纸复原:基于CNN的碎纸复原
By 苏剑林 | 2016-11-25 | 33717位读者 | 引用赛题回顾
不得不说,2013年的全国数学建模竞赛中的B题真的算是数学建模竞赛中百年难得一遇的好题:题目简洁明了,含义丰富,做法多样,延伸性强,以至于我一直对它念念不忘。因为这个题目,我已经在科学空间写了两篇文章了,分别是《一个人的数学建模:碎纸复原》和《迟到一年的建模:再探碎纸复原》。以前做这道题的时候,还只有一点数学建模的知识,而自从学习了数据挖掘、尤其是深度学习之后,我一直想重做这道题,但一直偷懒。这几天终于把它实现了。
如果对题目还不清楚的读者,可以参考前面两篇文章。碎纸复原共有五个附件,分别代表了五种“碎纸片”,即五种不同粒度的碎片。其中附件1和2都不困难,难度主要集中在附件3、4、5,而3、4、5的实现难度基本是一样的。做这道题最容易想到的思路就是贪心算法,即随便选一张图片,然后找到与它最匹配的图片,然后继续匹配下一张。要想贪心算法有效,最关键是找到一个良好的距离函数,来判断两张碎片是否相邻(水平相邻,这里不考虑垂直相邻)。
29
Jun
文本情感分类(三):分词 OR 不分词
By 苏剑林 | 2016-06-29 | 349470位读者 | 引用去年泰迪杯竞赛过后,笔者写了一篇简要介绍深度学习在情感分析中的应用的博文《文本情感分类(二):深度学习模型》。虽然文章很粗糙,但还是得到了不少读者的反响,让我颇为意外。然而,那篇文章中在实现上有些不清楚的地方,这是因为:1、在那篇文章以后,keras已经做了比较大的改动,原来的代码不通用了;2、里边的代码可能经过我随手改动过,所以发出来的时候不是最适当的版本。因此,在近一年之后,我再重拾这个话题,并且完成一些之前没有完成的测试。
为什么要用深度学习模型?除了它更高精度等原因之外,还有一个重要原因,那就是它是目前唯一的能够实现“端到端”的模型。所谓“端到端”,就是能够直接将原始数据和标签输入,然后让模型自己完成一切过程——包括特征的提取、模型的学习。而回顾我们做中文情感分类的过程,一般都是“分词——词向量——句向量(LSTM)——分类”这么几个步骤。虽然很多时候这种模型已经达到了state of art的效果,但是有些疑问还是需要进一步测试解决的。对于中文来说,字才是最低粒度的文字单位,因此从“端到端”的角度来看,应该将直接将句子以字的方式进行输入,而不是先将句子分好词。那到底有没有分词的必要性呢?本文测试比较了字one hot、字向量、词向量三者之间的效果。
模型测试
本文测试了三个模型,或者说,是三套框架,具体代码在文末给出。这三套框架分别是:
1、one hot:以字为单位,不分词,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-one hot”的矩阵形式输入到LSTM模型中进行学习分类;
2、one embedding:以字为单位,不分词,,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-字向量(embedding)“的矩阵形式输入到LSTM模型中进行学习分类;
3、word embedding:以词为单位,分词,,将每个句子截断为100词(不够则补空字符串),然后将句子以“词-词向量(embedding)”的矩阵形式输入到LSTM模型中进行学习分类。
25
Jun
OCR技术浅探:6. 光学识别
By 苏剑林 | 2016-06-25 | 59458位读者 | 引用经过第一、二步,我们已经能够找出图像中单个文字的区域,接下来可以建立相应的模型对单字进行识别.
模型选择
在模型方面,我们选择了深度学习中的卷积神经网络模型,通过多层卷积神经网络,构建了单字的识别模型.
卷积神经网络是人工神经网络的一种,已成为当前图像识别领域的主流模型. 它通过局部感知野和权值共享方法,降低了网络模型的复杂度,减少了权值的数量,在网络结构上更类似于生物神经网络,这也预示着它必然具有更优秀的效果. 事实上,我们选择卷积神经网络的主要原因有:
1. 对原始图像自动提取特征 卷积神经网络模型可以直接将原始图像进行输入,免除了传统模型的人工提取特征这一比较困难的核心部分;
2. 比传统模型更高的精度 比如在MNIST手写数字识别任务中,可以达到99%以上的精度,这远高于传统模型的精度;
3. 比传统模型更好的泛化能力 这意味着图像本身的形变(伸缩、旋转)以及图像上的噪音对识别的结果影响不明显,这正是一个良好的OCR系统所必需的.

最近评论