






 感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持!
感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持! 科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
28
Feb
生成扩散模型漫谈(十八):得分匹配 = 条件得分匹配
By 苏剑林 | 2023-02-28 | 18906位读者 | 引用在前面的介绍中,我们多次提及“得分匹配”和“条件得分匹配”,它们是扩散模型、能量模型等经常出现的概念,特别是很多文章直接说扩散模型的训练目标是“得分匹配”,但事实上当前主流的扩散模型如DDPM的训练目标是“条件得分匹配”才对。
那么“得分匹配”与“条件得分匹配”具体是什么关系呢?它们两者是否等价呢?本文详细讨论这个问题。
得分匹配
首先,得分匹配(Score Matching)是指训练目标:
\begin{equation}\mathbb{E}_{\boldsymbol{x}_t\sim p_t(\boldsymbol{x}_t)}\left[\left\Vert\nabla_{\boldsymbol{x}_t}\log p_t(\boldsymbol{x}_t) - \boldsymbol{s}_{\boldsymbol{\theta}}(\boldsymbol{x}_t,t)\right\Vert^2\right]\label{eq:sm}\end{equation}
其中$\boldsymbol{\theta}$是训练参数。很明显,得分匹配是想学习一个模型$\boldsymbol{s}_{\boldsymbol{\theta}}(\boldsymbol{x}_t,t)$来逼近$\nabla_{\boldsymbol{x}_t}\log p_t(\boldsymbol{x}_t)$,这里的$\nabla_{\boldsymbol{x}_t}\log p_t(\boldsymbol{x}_t)$我们就称为“得分”。
23
Feb
生成扩散模型漫谈(十七):构建ODE的一般步骤(下)
By 苏剑林 | 2023-02-23 | 40552位读者 | 引用历史总是惊人地相似。当初笔者在写《生成扩散模型漫谈(十四):构建ODE的一般步骤(上)》(当时还没有“上”这个后缀)时,以为自己已经搞清楚了构建ODE式扩散的一般步骤,结果读者 @gaohuazuo 就给出了一个新的直观有效的方案,这直接导致了后续《生成扩散模型漫谈(十四):构建ODE的一般步骤(中)》(当时后缀是“下”)。而当笔者以为事情已经终结时,却发现ICLR2023的论文《Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow》又给出了一个构建ODE式扩散模型的新方案,其简洁、直观的程度简直前所未有,令人拍案叫绝。所以笔者只好默默将前一篇的后缀改为“中”,然后写了这个“下”篇来分享这一新的结果。
直观结果
我们知道,扩散模型是一个$\boldsymbol{x}_T\to \boldsymbol{x}_0$的演化过程,而ODE式扩散模型则指定演化过程按照如下ODE进行:
\begin{equation}\frac{d\boldsymbol{x}_t}{dt}=\boldsymbol{f}_t(\boldsymbol{x}_t)\label{eq:ode}\end{equation}
而所谓构建ODE式扩散模型,就是要设计一个函数$\boldsymbol{f}_t(\boldsymbol{x}_t)$,使其对应的演化轨迹构成给定分布$p_T(\boldsymbol{x}_T)$、$p_0(\boldsymbol{x}_0)$之间的一个变换。说白了,我们希望从$p_T(\boldsymbol{x}_T)$中随机采样一个$\boldsymbol{x}_T$,然后按照上述ODE向后演化得到的$\boldsymbol{x}_0$是$\sim p_0(\boldsymbol{x}_0)$的。
16
Feb
Google新搜出的优化器Lion:效率与效果兼得的“训练狮”
By 苏剑林 | 2023-02-16 | 31575位读者 | 引用昨天在Arixv上发现了Google新发的一篇论文《Symbolic Discovery of Optimization Algorithms》,主要是讲自动搜索优化器的,咋看上去没啥意思,因为类似的工作也有不少,大多数结果都索然无味。然而,细读之下才发现别有洞天,原来作者们通过数千TPU小时的算力搜索并结合人工干预,得到了一个速度更快、显存更省的优化器Lion(EvoLved Sign Momentum,不得不吐槽这名字起得真勉强),并在图像分类、图文匹配、扩散模型、语言模型预训练和微调等诸多任务上做了充分的实验,多数任务都显示Lion比目前主流的AdamW等优化器有着更好的效果。
更省显存还更好效果,真可谓是鱼与熊掌都兼得了,什么样的优化器能有这么强悍的性能?本文一起来欣赏一下论文的成果。
先说结果
本文主要关心搜索出来的优化器本身,所以关于搜索过程的细节就不讨论了,对此有兴趣读者自行看原论文就好。Lion优化器的更新过程为
\begin{equation}\text{Lion}:=\left\{\begin{aligned}
&\boldsymbol{u}_t = \text{sign}\big(\beta_1 \boldsymbol{m}_{t-1} + \left(1 - \beta_1\right) \boldsymbol{g}_t\big) \\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t (\boldsymbol{u}_t \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}}) \\
&\boldsymbol{m}_t = \beta_2 \boldsymbol{m}_{t-1} + \left(1 - \beta_2\right) \boldsymbol{g}_t
\end{aligned}\right.\end{equation}
14
Feb
生成扩散模型漫谈(十六):W距离 ≤ 得分匹配
By 苏剑林 | 2023-02-14 | 15620位读者 | 引用Wasserstein距离(下面简称“W距离”),是基于最优传输思想来度量两个概率分布差异程度的距离函数,笔者之前在《从Wasserstein距离、对偶理论到WGAN》等博文中也做过介绍。对于很多读者来说,第一次听说W距离,是因为2017年出世的WGAN,它开创了从最优传输视角来理解GAN的新分支,也提高了最优传输理论在机器学习中的地位。很长一段时间以来,GAN都是生成模型领域的“主力军”,直到最近这两年扩散模型异军突起,GAN的风头才有所下降,但其本身仍不失为一个强大的生成模型。
从形式上来看,扩散模型和GAN差异很明显,所以其研究一直都相对独立。不过,去年底的一篇论文《Score-based Generative Modeling Secretly Minimizes the Wasserstein Distance》打破了这个隔阂:它证明了扩散模型的得分匹配损失可以写成W距离的上界形式。这意味着在某种程度上,最小化扩散模型的损失函数,实则跟WGAN一样,都是在最小化两个分布的W距离。
11
Feb
测试函数法推导连续性方程和Fokker-Planck方程
By 苏剑林 | 2023-02-11 | 15846位读者 | 引用在文章《生成扩散模型漫谈(六):一般框架之ODE篇》中,我们推导了SDE的Fokker-Planck方程;而在《生成扩散模型漫谈(十二):“硬刚”扩散ODE》中,我们单独推导了ODE的连续性方程。它们都是描述随机变量沿着SDE/ODE演化的分布变化方程,连续性方程是Fokker-Planck方程的特例。在推导Fokker-Planck方程时,我们将泰勒展开硬套到了狄拉克函数上,虽然结果是对的,但未免有点不伦不类;在推导连续性方程时,我们结合了雅可比行列式和泰勒展开,方法本身比较常规,但没法用来推广到Fokker-Planck方程。
这篇文章我们介绍“测试函数法”,它是推导连续性方程和Fokker-Planck方程的标准方法之一,其分析过程比较正规,并且适用场景也比较广。
31
Jan
Transformer升级之路:8、长度外推性与位置鲁棒性
By 苏剑林 | 2023-01-31 | 27430位读者 | 引用上一篇文章《Transformer升级之路:7、长度外推性与局部注意力》我们讨论了Transformer的长度外推性,得出的结论是长度外推性是一个训练和预测的不一致问题,而解决这个不一致的主要思路是将注意力局部化,很多外推性好的改进某种意义上都是局部注意力的变体。诚然,目前语言模型的诸多指标看来局部注意力的思路确实能解决长度外推问题,但这种“强行截断”的做法也许会不符合某些读者的审美,因为人工雕琢痕迹太强,缺乏了自然感,同时也让人质疑它们在非语言模型任务上的有效性。
本文我们从模型对位置编码的鲁棒性角度来重新审视长度外推性这个问题,此思路可以在基本不对注意力进行修改的前提下改进Transformer的长度外推效果,并且还适用多种位置编码,总体来说方法更为优雅自然,而且还适用于非语言模型任务。
12
Jan
Transformer升级之路:7、长度外推性与局部注意力
By 苏剑林 | 2023-01-12 | 53688位读者 | 引用对于Transformer模型来说,其长度的外推性是我们一直在追求的良好性质,它是指我们在短序列上训练的模型,能否不用微调地用到长序列上并依然保持不错的效果。之所以追求长度外推性,一方面是理论的完备性,觉得这是一个理想模型应当具备的性质,另一方面也是训练的实用性,允许我们以较低成本(在较短序列上)训练出一个长序列可用的模型。
下面我们来分析一下加强Transformer长度外推性的关键思路,并由此给出一个“超强基线”方案,然后我们带着这个“超强基线”来分析一些相关的研究工作。
思维误区
第一篇明确研究Transformer长度外推性的工作应该是ALIBI,出自2021年中期,距今也不算太久。为什么这么晚(相比Transformer首次发表的2017年)才有人专门做这个课题呢?估计是因为我们长期以来,都想当然地认为Transformer的长度外推性是位置编码的问题,找到更好的位置编码就行了。
4
Jan
智能家居之热水器零冷水技术原理浅析
By 苏剑林 | 2023-01-04 | 26654位读者 | 引用如果家庭使用单一的热水器集中供热水,那么当我们想要用热水时,往往需要先放一段时间的冷水,而如果放冷水时间比较长的话,就会比较影响体验。所谓零冷水,实际上就是想办法提前把热水管中的冷水排放掉,以达到(几乎)瞬间出热水的效果。事实上,零冷水并不是什么高大上的技术,但可能由于观念没跟上、理解上有误等原因,零冷水技术还没有在家庭中得到普及,不过随着大家对生活品质的要求越来越高,零冷水确实在慢慢流行起来了。
本文来简单分析一下零冷水技术的实现原理,包括各种方案的优缺点和自省DIY的参考思路。
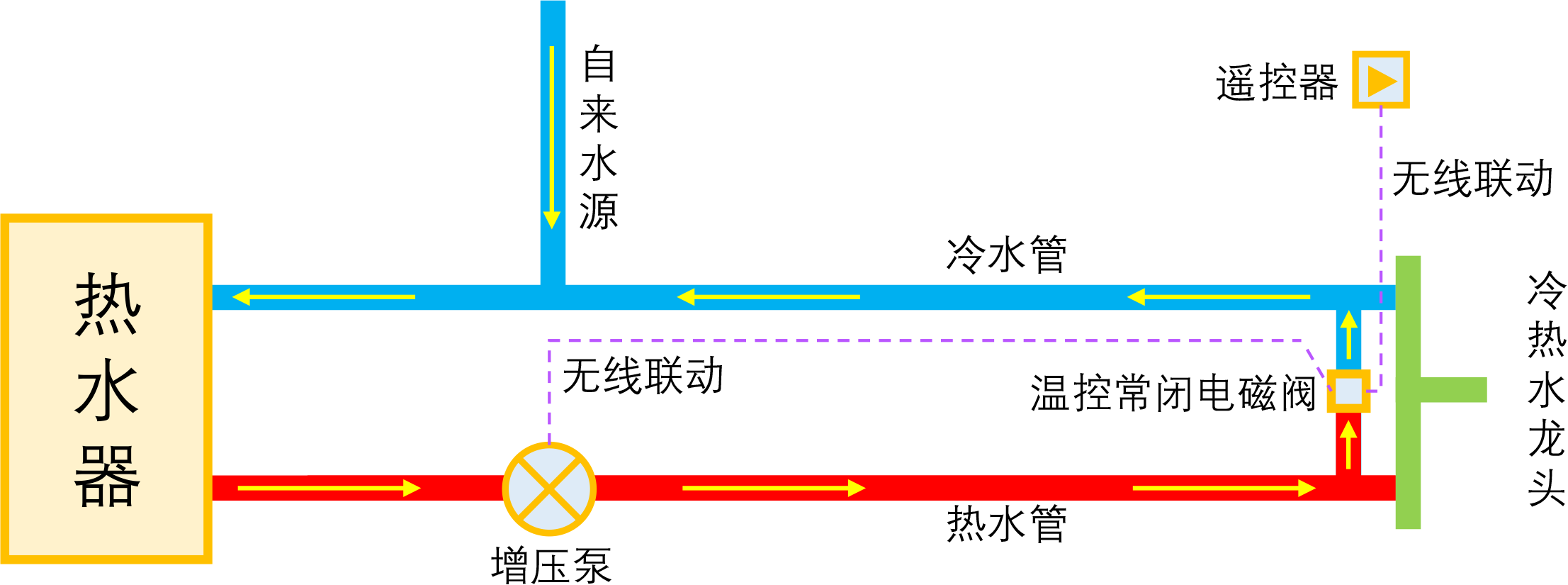
理想的零冷水方案
写在前面
在文章开始,需要纠正很多人的一个错误观念:零冷水不是为了省钱,而是为了提升生活品质。如果你是省钱最大的心态,那么接下来的内容就可以不用看了,零冷水技术对你毫无价值。

最近评论