






6
Jun
通用爬虫探索(二):落实到论坛爬取上
By 苏剑林 | 2017-06-06 | 22255位读者 |前述的方案,如果爬取的页面仅仅有单一的有效区域,如博客页、新闻页等,那么基本上来说已经足够了。但是,诸如像论坛这样的具有比较明显的层次划分的网站,我们需要进一步细分。因为经过上述步骤,我们虽然能够把有效文本提取出来,但结果是把所有文本放在一块了。
深度优先 #
而为了给内容进一步“分块”,我们还需要利用DOM树的位置信息。如上一篇的DOM树图,我们需要给每个节点和叶子都编号,即我们需要一个遍历DOM树的方式。这里我们采用“深度优先”的方案。
深度优先搜索算法(英语:Depth-First-Search,简称DFS)是一种用于遍历或搜索树或图的算法。沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
前一篇文章的DOM树,经过深度优先搜索后,各个节点和叶子的编号如下图。
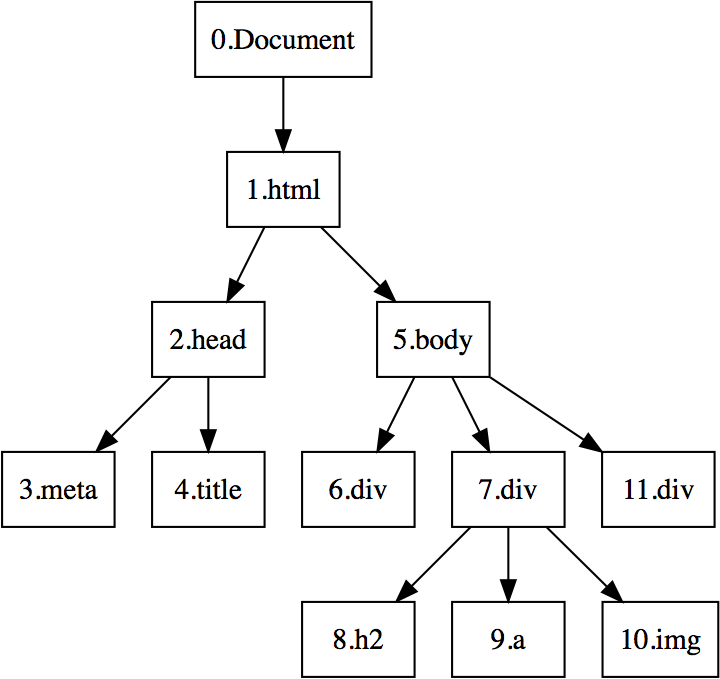
DOM树的编号
例外标签 #
给节点编号是为了后面的聚类,这我们自然希望同一类内部的编号差值越小越好。在众多HTML标签中,有不少标签仅仅表示强调、超链接等作用,如strong标签表示加粗,em标签表示斜体,等等,这些标签只会改变内容的样式,而不会改变内容的层级,因此,我们在遍历这些标签的时候,编号可以不变化,这样能够保证同一层级的标签之间更为相近,确保聚类的有效性。
我们列举的允许例外的标签如下表:
$$ \begin{array}{c|c}
\hline
标签 & 意义 \\
\hline
p/br & 换行\\
\hline
strong/b & 加粗 \\
\hline
em & 斜体 \\
\hline
font & 字体样式 \\
\hline
u & 下划线 \\
\hline
a & 超链接 \\
\hline
img & 插入图片\\
\hline
h1/h2/h3/h4/h5 & 标题标记\\
\hline
\end{array}$$
完整的例外标签列表,请直接查看源代码。
差分峰值聚类 #
通过前面的步骤提取的有效文本,并且经过上述深度优先的方式标号之后,就得到一个关于文本位置的序列。我们就会发现,同一个模块内的文本编号之差比较小,而不同模块之间的文本编号之差比较大。比如,同一篇文章的标题、日期、内容的位置编号很近,同一个楼层的回帖的标题、日期、回帖内容的位置编号也比较近,等等,如下图。这就诱使我们利用这个位置编号对有效文本进行进一步的聚类。
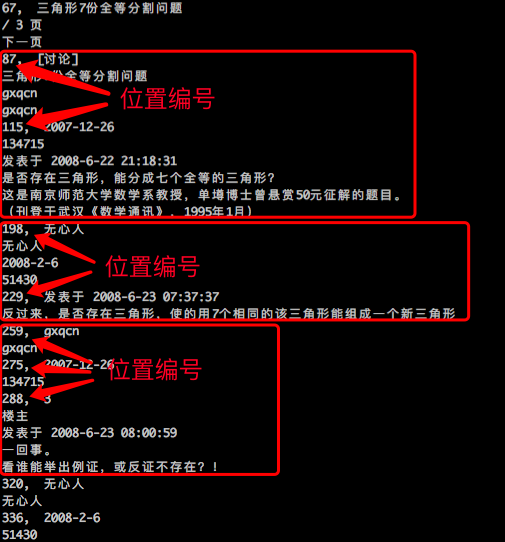
bbs的楼层划分
为此,我们考察位置序列的差分图,并且将实际情况的楼层分界线,用红色虚线描述出来,得到下图:
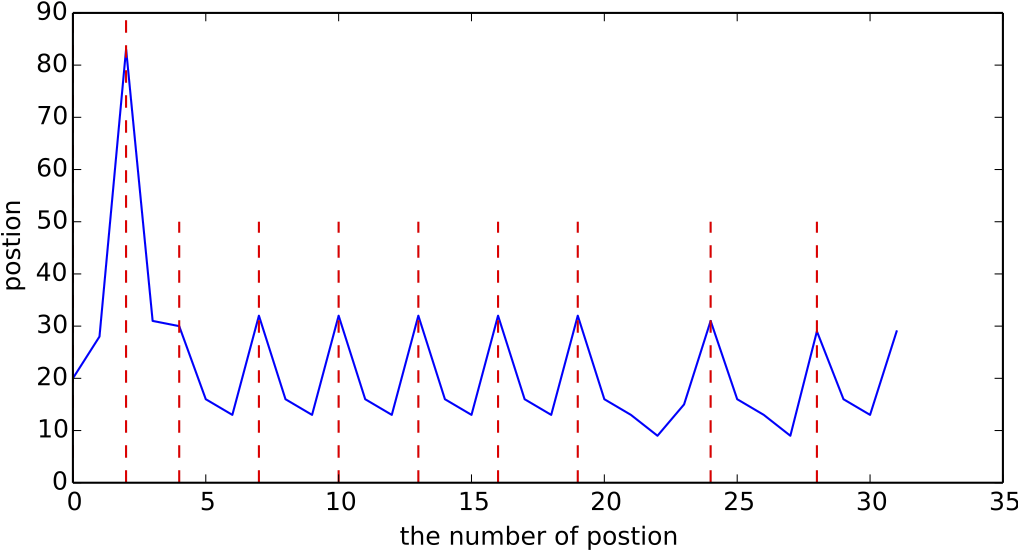
对位置编号序列做差分后,以差分序列的角标作为x轴,以差分结果作为y轴,所得的结果图。
上图显示了一个很明显的规律:每个楼层的分界线,基本就在差分序列的局部最大值处。因此,我们可以利用这个方案做切分式的聚类,即以局部峰值为分割点来对文本进行切分。这种聚类方式具有很好的特性,比如
1、能够自动确定聚类数目,即我们不需要预知究竟有多少个楼层;
2、自适应特殊情况,比如,倒数第二、第三个楼层相对其他楼层来说宽一点,是因为它的楼层之中还具有评论,即所谓“楼中楼”,所以导致内容更多一些,但即便如此,这个规律依旧保持着。
这说明,以这个规律来对文本进行分块,划分不同的楼层,是比较靠谱的。此外,这个聚类可以重复运行,以适应不同粒度的需求。事实上,对于论坛来说,大概需要重复运行1$\sim$2次,就可以得到楼层的划分了。
内容识别 #
最后,就是针对论坛本身,对每块文本区域的内容进行归类。为了不使爬虫复杂化,并且保证爬虫本身的效率,这里采用的识别方法相对来说都比较简单,是较为纯粹的规则分类。
标题 #
标题的识别相对简单,因为正常的页面的源代码中都有<title>字段,里边基本上都包含了完整的标题信息。因此,我们只需要直接通过正则表达式,把标题提取下来即可。
日期 #
在中文论坛中,日期比较常见的格式有几种:
2017-1-9 15:42
2017年 1月 9日 15:42
3小时前
昨天 20:48
其中前两种日期格式比较容易识别,后两种格式识别起来相对困难。后两种格式主要出现在某些论坛短时间内所发布的帖子中,一般过了一两天后,就会自动复原为前两种格式。
这时候,依旧从简单和稳定性的角度出发,我们可以采取一个折中的策略,即对这部分网站的短期内的帖子不识别日期,直接混合保存,而从持续监测的角度来看,一两天后,我们就能够把日期识别进来。这样既不影响监测的实时性,又能使得程序更为简单可靠。
作者 #
事实上,作者(发帖人)识别起来比较困难,我们并没有找到有效的算法来完成一个通用的作者识别模型。另外,我们也考虑到对发帖人的识别的价值并不是特别大,所以最后我们放弃了这部分识别工作。
正文 #
识别出时间后,通过时间将单个文本区域再次断开为上下两个半部分,我们认为,上下两部分之一为正文内容。为了识别正文内容在哪一半,我们分别对上下两半全局进行统计,比较哪一半所含的中文居多,居多的部分,即为正文部分。
当然,从更严谨的角度,可以按照前一篇的学术思路,使用语言模型判断哪部分更接近于自然语言,从而确定哪部分才算是正文部分。但这个方案效率偏低,而且我们主要关心的是中文内容的爬取,因此我们的实验中,排除了这个方案。
转载到请包括本文地址:https://kexue.fm/archives/4422
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jun. 06, 2017). 《通用爬虫探索(二):落实到论坛爬取上 》[Blog post]. Retrieved from https://kexue.fm/archives/4422
@online{kexuefm-4422,
title={通用爬虫探索(二):落实到论坛爬取上},
author={苏剑林},
year={2017},
month={Jun},
url={\url{https://kexue.fm/archives/4422}},
}

最近评论